もじもじカフェ 戸籍と住基とマイナンバーの文字コード
もじもじカフェ第38回「戸籍と住基とマイナンバーの文字コード」に参加してきました。
もじもじカフェは「文字と印刷について市民と専門家・業界人がお茶を飲みながら気楽に話し合う」というイベント。
勉強会とかセミナーとは違って「お茶を飲みながら気楽に」というスタイルなので、会場もこぢんまりした喫茶店のようなところで、講師を中心に皆で大きなテーブルを囲んで話をするスタイル。
今回のテーマは「戸籍と住基とマイナンバーの文字コード」京都大学の安岡孝一氏を講師に現在策定が進められているマイナンバー制度などを文字コードの視点から説明してもらいました。
大変面白かったので、いつものようにレポートを。
このレポートは当日の安岡先生の話を私の手書きメモから書き起こしたものです。
聞き落とした部分もありますし、私が聞き間違えている可能性もあります。
大体こんな話だった程度の物と思ってお読みください。
もし何か間違いを見つけた人は教えてください。
戸籍で使える文字「戸籍統一文字」はどうやって決まったか
この中で自分の戸籍を見た事がある人?(数名が手を挙げる)それは縦書きでしたか横書きでしたか?(ほとんどが縦書きと答える)
それは電子化前の戸籍ですね。現在、戸籍の電子化が進められているのだけど、電子化がすんだところは横書きででます。縦書きは電子化前の物。
今、市町村の数は1740ちょっとぐらいあるのだけど、1707、8市町村はすでに電子化が終了しています。
まだ電子化終了していないとこというと、例えば京都はまだです(古い名字が多くて電子化が難しい)
あと、夕張市もまだです。これは理由は分かりますね(笑)(経済破綻した市なので予算がない)
戸籍を電子化するためには、まず電子の戸籍に使える文字を決める必要があります。
電子化するにあたって、法務省で戸籍に使える文字の検討をしていった訳だけど、最初は正字、常用漢字、人名用漢字、漢和辞典に正字として載っているものを使える文字としようと考えたのだけど、これがたとえばはしご高(髙)なんかも使いたいといって衆議院でもめて、それで、俗字も許すという方向になった。ただし何でも許した訳ではなく「漢和辞典に載っていれば俗字でも可」とした。
辞典に載っていないやつとか、載っていても「これは誤字である」と記載されているやつは認められない。
こういう方針を決めて、2001〜2003年頃に使ってもよい漢字の洗い出し、大漢和辞典とかの文字から使う文字を全部洗い出していった。
これで決められたのが、戸籍で使うための独自文字コード「戸籍統一文字」
洗い出した5万字ちょっとの漢字、ひらがな、変体仮名などに6桁の数字を振っていった。
使えない文字を戸籍で使いたいときは
戸籍が電子化される時には、今、紙の戸籍に載っている文字が「戸籍統一文字」にあるかどうかを判断します。
「誤字俗字・正字一覧表」というのがあります。これは明治ぐらいから総務省で作っている表なのだけど「この文字はこの文字の俗字である」と判断するのに使う一覧表になっています。俗字と判断されれば、電子化の際には正字に置き換えることになる。
戸籍を電子化する際に、字が(俗字から正字に)変わってしまう人にはその戸籍の筆頭者に「あなたの名前は電子化されると字が変わりますよ」と連絡します。
これを拒否するとこの戸籍はコンピュータ化できないので、「事故簿」という扱いになります。つまり紙のまま運用していくということになる。
こういう「事故簿」が大体1%ぐらいは残ります。
ただし、この事故簿の人でも新しく戸籍を作る時、つまり結婚する時ですね、この時は字が変わるのを拒否する事は出来ません。ですので、事故簿として紙運用しなければならないのは、今その戸籍に入っている人だけです。新しい戸籍には引き継げませんので、あと何十年かすればすべての戸籍がコンピュータ化できるはずです。
しかし、実はこの事故簿を引き継ぐ方法というのもありまして、結婚すると戸籍が変わるので、結婚せず今の戸籍のまま、子孫を残したい時には奥さんも生まれた子供も養子という形で戸籍に入れます。こうすると理論上新しい戸籍を作らず事故簿を引き継げるという事になります。
実際にそうやって字を変えたくないからと言う理由で養子をとって戸籍を残している人がいるかどうかは知りません。
戸籍の電子化の際、字が変わる場合は筆頭者に連絡がいくわけですが、まず連絡をするというのが大変で、なぜなら戸籍というのは本籍地しか載っていないわけで、つまり現在そこに住んでいるかどうかは分からない。現住所を調べるためには戸籍の情報から住民票の情報につながらなければならないですが、これは住民基本台帳の方にそこがつながっている情報がある。ですからそちらと連携して調べるわけです。
住民基本台帳はどうなっているか
住民基本台帳については2002〜2004年でコンピュータ化がすべて完了しています。
現在の住民票はすべて、とにかくすべての文字にコードがふってあります。これが住基コード(住民基本台帳ネットワーク統一文字)。
住民票のシステム化というのは、各自治体がそれまでにそれぞれでやってたりするのですが、住基コードではそこのシステムで使われていたような(様々なメーカーの)外字をとにかく全部持ってきて、ちゃんと精査せずにならべてしまった。
だから字形がだぶっている文字がかなりあるし、そもそもコード化できず画像として持つしか無い文字もある。これは48×48ドットの画像ファイルとして持たせて運用してる。
マイナンバーはどうなる
今、マイナンバー制度というのがスタートしようとしていますけど、これは総務省つまり住基ネットをやってるところがやろうとしてる。住民票を元に個人に番号を振る。戸籍のほうをやっているのは法務省。なので、法務省はいまいちマイナンバーに乗り気ではないんです。戸籍電算システムはマイナンバーには参加しません。
さて、マイナンバーで使われている文字コードは、ユニコードを使うことになりました。なぜ住基ネットで使っているコードをそのまま使わなかったのかというと、住基コードは一部コードでUnicodeの他の文字とかぶっているなどの問題があり、Windows XPでしか動かせないという制約があるからです。
(参考:住民基本台帳ネットワーク統一文字とその問題点 https://www.jstage.jst.go.jp/article/johokanri/55/11/55_826/_pdf)
しかしユニコードを使うといっても、当然足りない字形がでてくる。これをどうするか?
ユニコードで異体字を表現するにはIVSという技術があるわけですが、しかしマイナンバーのシステムを作っている人たちはこれは難しくて使えないと言って、採用しなかった。
ではどうするかというと、ユニコードにはF0000からの外字領域というのが用意されているわけですが、ここに入れてしまおうと言う話になりつつある。
それでも残る問題として、コードを当てられない文字、48×48で運用しているような文字ですね
例えばしんにょうに鳥と書いて渡なべさんのなべと読むっていう字がある。

▲しんにょうに鳥、で「なべ」
これ(手書き略字で)いくとこまでいっちゃうと邉はこうなるっていうような文字なんですけど(笑)これなんかも今は48×48で運用してる。こういうのを正式に(マイナンバーのコードとして)入れるつもりはない
他に変体仮名の問題もあります。今これを使われているのが1千弱ぐらい。
中でも濁点のついた変体仮名は住基コードにはない。これをどうするのかも決まって無い。
変体仮名の名前ってのは昭和30年ぐらいまでは女性の名前なんかで使われてたんですね。でもこれがよみがなもないし、なんて読むのか音もわからない。
こういうのはもう、48×48の画像で運用するしかない。
今のところマイナンバーについての議論というのは「いかになりすましを防ぐか」とか「個人情報の流出を防ぐか」というところに終始していて、こういった文字コードについてはなおざりにされているという状況です。
――ここから、参加者からの質問などに答える形に。トピックとしてメモしたものを載せます。文中四角罫でかこった部分は私の補足です。
マイナンバーでIVSを使わなかったことについて
IVSはUnicodeの後ろにvsという字体選択コードをつけるわけだけど、これはアプリケーションからすると、一つ目のコードで文字が確定できなくて、二文字分よんでから後ろにもどって字形を確定させるという処理になるから難しい
IVSは通常のUnicodeの後ろに字形を指示するコード(VS)をつける
これをアプリケーションで扱うには、二つのコードを読んだ後、それが異体字を示しているのか、他の文字なのかを判断しなければならない。これが実装的に難しいらしい。例えばInDesignではIVSに(一応)対応しているが、この二つのコードの扱いは難しいらしく、Unicode+VSで一つの文字のはずなのに、なぜかVSの前にカーソルが入ってしまうという動作になる。だからDeleteキーを押した時に文字が消えずにVS(異体字情報)だけが消えてしまう

IVSにしても何にしてもそうだけど、大量の異体字を扱える状態だとその中から目的の字形を見つけるのが大変になる。字形が用意してあっても見つけられないということもある。
これは入力の仕掛けというか、字形を探し出す部分のインターフェースをもっと考えなければならない。たとえば部品からの検索で入力できるとか。いまそういった入力についてもメーカーと共同でテストしているところ
人名ではなく地名の漢字の扱いはどうか
地名については、出来るだけゆらぎをなくすということで、各自治体にがんばってもらっている。基本的には統一していく方向で。
ただし葛城市のような不幸な例は残ってしまう。あそこは先日聞いたら「(字を変えるかどうか)市民投票する」みたいな話をしてて、いや、那覇とかだって字を変えるのに別に市民投票なんかなしでいつの間にか変えちゃってるんだから、そんなことしなくていいだろって言ったんですけど。
基本的に町名のようなものは常用漢字などの簡単なものに合わせていくようになる
奈良県葛城市は、「葛」の字を略字である「葛(下の部分がヒ)」を採用。
これは2004年の合併時「パソコンなどで表示される「葛(下の部分がヒ)」の方がいいだろう」とわざわざその字にしたのに、VistaからのJIS2004採用での字形変更で「パソコンで出ない文字」に戻ってしまったという経緯があり「JIS2004で一番混乱した例」としてよく引き合いに出される
中国など他の漢字圏での戸籍事情は?
中国は漢民族は漢字だからまだいいが、1/3はそれ以外の民族で、別の言語を使っている人もいる。
こうなるとコンピュータ化は難しいから戸籍も手書き運用するしかない。
ただ、あそこは基本的に居住地が定められていて移動の自由が許されていないから、戸籍が紙運用なのはそれほど困らない
漢字で管理できない文字は、パスポートを持つ時は困るんだけどそれはアルファベットの表示になる
困るのは日本の人と結婚してかつ中国籍のままの時。戸籍には「○○と結婚しました」という情報をのせなければならないのだけど、戸籍統一文字にある範囲の文字しか使えないのでそこに収まらない人はカタカナかアルファベット(A-Zの大文字のみ)で表記する。ウムラウトなんかもそう。表示できないからドイツの人の名前はアルファベットかカタカナに開いてのせる事になる
住基ネットで使っているXPでしか動かせないシステムはこれからどうなるのか
どうしようもできないので、XPマシンを取っといて使うしかない。クローズドシステムでインターネットには絶対つながないとか…。
OSをクラウド化してXPを永久に使うみたいな話もあったがさすがにそこまではしないと思う。
養子をとって戸籍をつなぐという方法について
養子をとって戸籍を引き継ぐというのをやっている戸籍としては、樺太戸籍はそうやってまだ生き残っているのがいるらしいです。なぜその戸籍を引き継ぎたいか?希少性とかじゃないですかね?これはもういまから作ることはできないですから。外務省はもうやめて欲しがってると思いますけどね。満州戸籍なんかはもう強制的に廃止になってるんですけどね。
樺太戸籍
昔日本の領土であった時代に樺太などで生まれた人は樺太が本籍地となる戸籍を持っている。
戦後、そのうちの一部は日本に持ち帰られ外務省に保管されている。必要であればその写しを請求することができる。
文字コードを作る際に文字の順番ってどうやって決めるのがいいのでしょう
どうやってといっても、部首、画数順、康熙字典順ぐらいしかないのでは
戸籍統一文字に入れる文字の根拠として「辞書に載っていればOK」とすると増えすぎて困らないか
そこの判断としては常用漢字表で定められている「デザイン差」の判断を基準としている。
でも自分の名前の字形にこだわる人というのは多くて、たとえば「樹」という字の真ん中が「土」か「士」かでもめる。でもこの字は「十と豆」であって「土」でも「士」でもないんです。ほんとは。
でもこの「土」か「士」の違いを「先祖が武士だったか農民だったか」の違いだと思ってる人がいて、それでもめる。そういう俗説を信じちゃう。
戸籍統一文字や住基統一文字に文字が追加されたのはどうやってわかるのか
戸籍統一文字に文字が増やされる時は法務省の民事局がだまって追加してる。
でも戸籍統一文字はWebですべて公開されているので(http://kosekimoji.moj.go.jp/kosekimojidb/mjko/PeopleTop)毎日そこで戸籍統一文字コードの最後の文字をチェックしてれば新しい文字が追加されたのはわかる。
住基コードの方はもっとひどくていつの間にか増える。増えましたよって通知を総務省が出す前に、現場に新しいフォントが持ち込まれたりする。
文字を追加するのは「自分の名前はこの字ではない」という本人の申し立てがあって追加されるが、申し立てた人はその時点で古い文字で電子化されてしまっているので、その字が追加されても変更することはできない。
行政で使われている文字コードの仕様は公開されているのか
戸籍統一文字はWebで公開されています。住基統一文字は全く公開されていません。
ただし、各市町村自治体に台帳があるので、申し込むとコピーを取らせてくれることはあります。
各自治体で使われているローカルな文字環境についても、自治体に情報公開請求すれば見せてもらえます。ただ、いきなり「文字コードみせてください」といっても断られるかもしれないので「セキュリティ関連の情報と文字コード関連の情報見せてください」みたいにいうと「セキュリティは見せられないけど文字コードぐらいなら…」という感じで見せてくれることが多い。
文字コードを公開しない理由と、公開しない権利は自治体にあるか?例えば裁判などで訴えたりできるか
自治体が文字コードを公開しない理由については、特に根拠はないとおもいます。わざわざ見せたくないというぐらいでしょう。
裁判するといっても、するとしたら「知る権利が阻害された」とかになるかもしれませんが、先ほども言ったように申し込めば見せてもらえることがほとんどなので、それは通らないと思います。
戸籍の電子化が一番大変な地域は京都でしょうか?(古い名前、地名が多いため)
大変さでいったら、いろんな人が流入している東京が一番大変だったと思いますが、東京はお膝元ということもあって、一番先にデジタル化に着手し、終了しましたから。
ですから東京は事故簿も多いです。ある区では2%ぐらい事故簿になったのでは。
京都は今電子化をすすめていますが、東京の事例を見ていますのでそこを参考にできるというのはある。
大変さでいったら沖縄なんかも大変だった。あそこは戦争で戸籍がなくなってしまったところからだったので、混乱期に作られた戸籍でダブりとか横書きになってるとかそういう戦後のエグさがあった。
住基統一文字には「家」が4つ登録されているが、これはデザイン差ではないのか
それまで使っていた大型コンピュータ、富士通のJEFとか日立のKEISとかのホストコンピューターシステムの文字をそのままもってきちゃったのでだぶっている
こういった文字コード、文字セットを策定、保守しているのはどういった立場の人なんでしょう
………単なる漢字好き。
日本で10人よりは多いけど100人はいないぐらいの人数。実際いろんな会議とかでると同じような顔ぶればかりみるし。
中央で文字を整理している人は知識も経験もあるからどんな文字があるかなど分かっているが、末端でその整理された字を使う人はそれが分からずどんどん新しい字を追加してしまう。だからいくら整理してもきりがない。
多くの字を整理して用意しても、その中から自分の必要な文字を探し出せない。多分必要なのは、分かりやすい字形の検索システム。
結婚時に戸籍が新しくなって名前の字がかわると困る人はどういう人か
よくあるのは会社の登記簿などにのせている字と変わると困るというケース。これは実務的に困る。
あとは個人のこだわり。普段使っている字は正字でこだわらなくてもパスポートや住民票など公のものに関しては譲れないという人は多い
【感想】
うーーん、IVSにAdobeJapan1とは別の汎用電子というIVDが用意されていると聞いてから「では今後、官公庁関連の名簿なんかではそれが使われるのか?その場合AJ1ベースの印刷データとのやり取りはどうなるのだろう?」とか思ってたんだけど、今回の話を聞く限りとてもそんな段階にない。っていう感じだなぁ。
電子化にしても、新しい戸籍を作ると強制的に正字に統一される戸籍に比べて、住民票のほうはとにかくなんでもそのまま電子化しちゃうみたいで、今後これが整理されるとは思えないし。しかもマイナンバーは基本的に住民票をベースにしていて戸籍とは連動しない。
マイナンバーの議論では文字コードについてはなおざりにされてるということらしいけど、せっかくIVSという技術があるのに、それを使わずUnicodeの外字領域に全部いれちゃうとかダイナミックすぎるだろう…。こういうのって、後々トラブルの元になったりするんじゃないかなぁ…。まぁ、確かにIVSも出来たばかりの規格で今後どうなるか分からないから採用するのは勇気いるけど。
んでも、そのトラブルの元がボディーブローのように効いて苦しむのは私らみたいな印刷屋とかだったりするんだよな☆
CSS3での日本語縦中横を考える
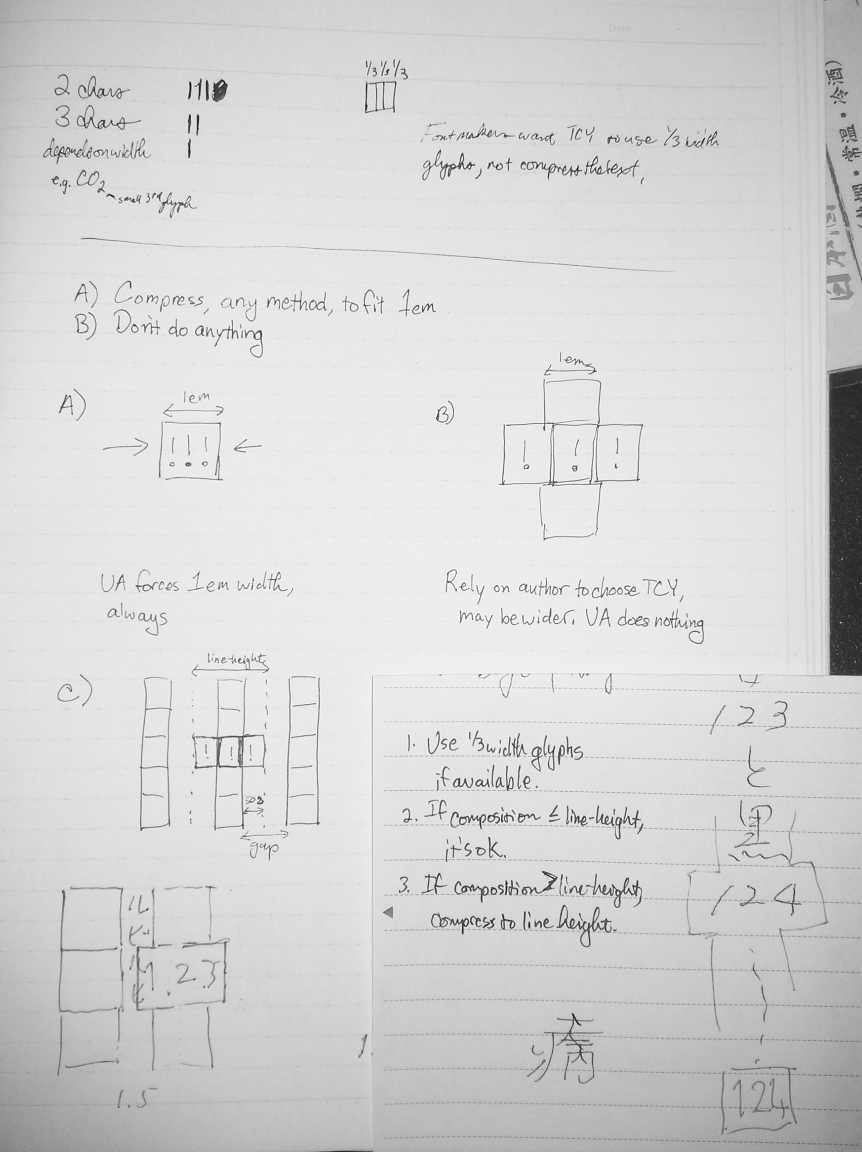
【問題】
日本語縦組で文字が縦中横されたとき、組まれた文字の文字幅はどうなっているのが正解か
A. 1文字の幅(1em)に納める
B. 何もせずそのままの幅にしておく
▲(左)A. 1文字の幅(1em)に納める (右)B. 何もせずそのままの幅にしておく

何の話をしているのかというと、これ、、CSS Writing Modes Level3で定義される日本語縦組での縦中横の処理の話である。
先日、村上さん、小形さんお二人の呼びかけで「fantasai(ファンタサイ)さんを囲む夕べ」という飲み会が開催されました。
W3C CSSWG Tokyo F2Fのため来日中のfantasai twitter.com/fantasai/statu… を囲む夕食会を来週に計画してます。興味ある方は私にDMください。
— 村上真雄 MURAKAMI Shinyuさん (@MurakamiShinyu) 2013年6月7日fantasaiさんはイラン系アメリカ人の女性で、CSSの他言語対応(もちろんその中には日本語も含まれる)に尽力なさっている方。
彼女が来日したのに合わせて、せっかくなのでお食事でもご一緒しましょうという企画です。
参加者は小形さん、村上さん含め10名程度。それぞれフォントの制作者、タイプデザイナー、組版のエキスパート、EPUB制作のエキスパート、文字コードなどのエキスパート、EPUBリーダーの制作者など、様々な立場から日本語組版に取り組んでいる人たち。(ちなみに私はなんのエキスパートでもありませんが……fantasaiさんにはDTPオペレータと紹介されました)
つまりこの飲み会は「CSS3策定に携わる方に実際に日本語組版を行う立場の者が話をしよう、話をきこう」というもの。
そしてその場でfantasaiさんから参加者に出された質問が冒頭の問題。これ、現在CSS3で議論されている日本語の縦中横の仕様についての質問です。
私はこの問題について
- CSS3の仕様ということで、ここの仕様はWebブラウザやEPUBリーダーでの縦組表示の規準となる。つまりユーザーが自由に行間、フォントサイズを設定する環境で使われるものである
- 通常の縦中横(2桁あるいは3桁)であれば、長体をかけて1em幅に納めてしまった方が、どんな行間設定であっても隣の行のルビなどに重なる心配がない
という観点から「A. 1文字の幅(1em)に長体をかけて納める」に1票を入れました。
ですが参加者の意見は割れまして、確かAに4票、Bに2票、その他が2票。
A以外を選んだ人の意見は確か「フォントに長体をかけて欲しくない」というのが主な主張だったと思う(多分字形の見た目の問題?その主張については具体的な理由はわからなかった)
面白かったのは「フォントに長体をかけて欲しくない」うち「その他」を選択した二人の意見で「日本語フォントにはそのためにデザインされた二分三分四分幅の数字字形が用意されているのだからそれを使って欲しい」というもの。
この意見は参加者のうち、タイプデザイナーとフォント制作者という「フォント制作に関わる人たち」が主張。なるほど、フォントを作っている人からすれば「せっかく組んだ時に美しくなるようにグリフを用意しているのだからそれを使って欲しい」と思うのは当然だろう。この「グリフが用意されているならそれを使う」という条件には全員が同意。
ただし、これはCSS3という規格の為の質問なので、この仕様を使うのは主にWebブラウザーやEPUBリーダーなどであり、そこの表示につねににグリフをもった日本語フォントが用意されているとは限らない。
問題は二分三分四分幅のグリフをもたないフォントで表示されたときはどうするか?
ここの意見はなかなかまとまらず、紛糾。
私は上にも述べたように「ユーザーが行間を調整したときに、隣の行のルビと重なる恐れがある」のが嫌だったので「1em幅に納める」を推したんだけど、長体をかけて納める事を良しとしない主張の方もいて、どうしてもまとまらない。
時間もあまり無い中(この質問は食事会の後半になって出されたので)とにかくその場の参加者の総意をまとめなければならないという事でその場でだされた折衷案
(1)もし(二分三分四分幅といった)狭い幅のグリフがあればなるべく1em幅に収まるようそれを使う。
(2)縦中横にした幅≦行高(前後の行間アキを半分ずつ含む)であればそれを許容。
(3)縦中横にした幅>行高であれば、行高(前後の行間アキを半分ずつ含む)に収まるように幅を圧縮。
つまり行間の半分までははみ出す事を許容する、という案。
結局この案だと、1em幅からのはみ出しを認めているので、ユーザーが行間を狭くした時となりの行のルビ等と重なる恐れがある。

▲(左)行間の半分までははみ出しOK。それ以上は長体 (右)用意されている二分三分四分幅グリフを使用
私はルビが重なったりするのは嫌だったんだけど、結局「縦中横の桁数、文字数については制限はないので、5桁以上の組数字、組文字もありえる」という条件から、すべて1emに押し込めるのはムリかもしれないということでこの案に同意しました。
さらにこの合意はCSS3の縦中横の規格のためのもので
・CSS4以降でもっと細かな調整が可能にしたいと考えている。
・しかし、それをするためにはまずCSS3を勧告にすることが必要。
という説明がfantasaiさんからありました(つまり、今回決めた規格は今後変更可能であるが、とりあえず今規格を決める必要がある)
この場で合意した内容について、翌日fantasaiさんがcss-writing-modes のMLに投稿しています。(http://lists.w3.org/Archives/Public/www-style/2013Jun/0207.html)
以下その内容
[css-writing-modes] Tate-chu-yoko sizing rules
昨日、村上さんは、10人の日本のタイポグラファ/タイプ・デザイナー/DTPオペレータのグループと、私を夕食に招待しました。
自然に、私はその日の問題(縦中横)について、彼らに説明しました。我々は、2つのオプションから(話を)始めました、
A)1emに押し込む
B)何もしないテーブルは4対2に割れました、しかし、2人の他の人は「場合による」というオプションC)を強く要求しました。
日本語の多くの議論の後、テーブルのグループは、以下のルールについてのコンセンサスにたどり着きました:
(1)もし(二分三分四分幅といった)狭い幅のグリフがあればなるべく1em幅に収まるようそれを使う。
(2)縦中横にした幅≦行高(前後の行間アキを半分ずつ含む)であればそれを許容。
(3)縦中横にした幅>行高であれば、行高(前後の行間アキを半分ずつ含む)に収まるように幅を圧縮。私は、ラインハイトが狭すぎる場合、縦中横とルビがくっついてしまってもOKかと尋ねたところ、彼等はそれが許容できると言い、それが彼等の必要とするルールであることを私に保証しました。
我々が議論のために使ったスケッチは、ここにあります:
http://lists.w3.org/Archives/Public/www-archive/2013Jun/att-0069/shinjuku-2013-06-11.pngこのコンセンサスを反映するためにCSS Writing Modesを編集したいと思います。これに対して異議がありますか?
この投稿に対して、MLの他の参加者からは、現在すすめようとしているLevel3の仕様「1emに収めるようにすること、でも方法は何でもよい。1/Nグリフを使うか、圧縮するかどうかなど、特に定めない」のままでよいのではないか。それ以上の機能についてはLevel4で設定すればよい。といった意見が出ているようです。
私も、とりあえずLevel3では「1emにおさめる」でいいような気がしています。
確かに5桁以上の文字数が来たりするとかなり読みにくくなるのだけど、そもそもそんな桁数を縦中横に入れるのが間違ってると思うので、そういう意味では読みにくくなる方がいいのかもしれない。
あと、二分三分四分幅のグリフを使うというのはかなりきれいな解決なのだけど、ある種、必要以上のこだわりと取られてしまうのではないかということ。(これ、CSSで決めなくてもそういう表示にこだわりのあるReaderだったらそこに個別に実装すればいいのではないか?それって難しいの?)
しかしこの件については、正直もっと議論というかいろんな人の意見が必要だと思う。少なくともあの場のあのテーブルで出た意見だけがすべてではないと思う。
縦中横については、数字だけではなく欧文、および日本語であっても設定可能という条件なので、数字はともかく欧文のときもこの条件でいいのか?という疑問もあります。
と、いうか今回こういう議論に思いもかけず参加することになって思ったけど、こういう規格ってなんとなく雲の上の「すごくよくわかってる人」達が決めてるんだろうと思ってたの。
だから、私たちが意見を言わなくたってちゃんとしてくれるんだろうと思ってたし、なんか変な規格(先日あった、日本語の縦組でイタリックを指定するとか)が通りそうとかいう噂が聞こえてくると「え、ちょっとだれか偉い人、ちゃんとしてよ」という「自分にはどうしようもないけど、だれかなんとかして」という感じだったの。
でも実際、飲み会の場でわいわいと決めた意見をMLにとりあげて貰った事で「え、規格って意外と身近なところで決まってるの?そんで私たちの意見も聞いてもらえるの?」という、なんていうかスーパーモデルだと思ってたら、実は隣にすんでるねーちゃんだったみたいな身近感が!正装しなけりゃ入れない高級レストランかと思ってたら、中はお手頃価格のビストロ居酒屋だったみたいな気安感が!やだ!これならしょっちゅう食べに来れるじゃない!通っちゃおうかしら!よーし、パパCSS3の仕様について勉強しちゃうぞー!!!
でも、実際には全部英語なんだよねー…
(立ちはだかる語学力の壁。遠のく親近感)
あ、ちなみに当日の議論は全部日本語で、fantasaiさんには村上さんが通訳をしてくださるという状況でした。村上さん、ありがとうございました。
JEPA 国際 デジタル教科書 技術ワークショップ
JEPAのセミナー「国際 デジタル教科書 技術ワークショップ」を受けてきました。
内容が面白かったので、まるっと書き起こしレポート。
例によって、やたら長いので、全部読めないという方は最後に私の感想とまとめをおいときますので、そちらをごらんください。
まるっと書き起こしといっても、すべて私の手書きメモからの書き起こしですので、当然細部に違いはありますし、書き漏らした部分もあります。大体こんな感じだった程度に思ってください。
このセミナーに関しては、当日の資料と映像すべてが公開されています。興味のある方は是非そちらをご覧ください。特にデモ部分などはテキストの書き起こしでは表現できませんので。
「欧州の教科書標準化動向」
Markus Gylling(IDPF CTO EPUB Working group 議長、DAISY Consortium CTO)
IDPFのCTOでありEPUBの規格を制定するワーキンググループの議長のMarkus Gylling氏より
教育現場にデジタル教科書(教科書そのものというより、デジタル教科書を使った教育システム)を導入するためにどういった物、技術が必要なのか、何が問題となっているのかをヨーロッパ、アメリカの事例を交えて紹介
Markus Gylling:元々の講演依頼では「ヨーロッパの事例」という事でしたが、ヨーロッパだけでは事例が少なくて話がすぐ終わってしまうので、アメリカの事例も含めておはなしします。
今日私が話す内容がすべての事を網羅しているわけではないが、その辺は他の方の話と合わせれば全体像がわかると思います。
デジタル教育のシステムを導入すること自体は難しくありません。ただし、それは一社のシステムのみを使う時です。
一社のみで、コンテンツ、サーバー、サーバーアプリすべてを提供しそれを利用するなら簡単です。
しかし一社のみですべてを賄うというのは、その一社に縛られてしまいそこから抜け出すのは大変です。そもそも一社独占というのが非合法になる場合もあります。
ですから(システム、規格の)標準化というものが必要なのです。
(デジタル教科書を利用した教育システムを構築するにあたって)ベンダーに縛られず、中立であるために必要な物
- サーバー
- 閲覧するための端末、リーダーソフト
- コミニケーションプロトコル
- コンテンツ
この中でコミニケーションプロトコルについて、システムに必要な機能は以下のものが考えられる
・コンテンツ(教材)の発行に伴う権利を付加する機能が必要
・どんなカリキュラム、コースであるかの管理
・クラウドベースでの(クライアントの)状態管理
生徒がどこまで進んでいるか理解できているかの把握
・宿題をどのように割当て、管理するか
生徒の理解度などによって、適切な宿題を出す、またその提出などの管理
・テストをどうやって実施するか
・生徒や教師が教材に注釈を自由に入れられる、その注釈をお互いに見たり、自分だけで見たり、特定のメンバーで共有したりできる
さらに、いくつかの必要条件があります
・デバイスについて、どのデバイスでも問題なく動く必要がある
・トレードブル、「ここがわからない」というコメントに先生や生徒がコメントをつけられること
・マルチモーダル、テキストだけでなく、絵や音声をつける事が出来る必要がある
・権利とオーナーシップ、誰がそのコンテンツの権利を持っているかの情報管理
・シェアリング、一人がアクセスするか、誰でも見られるか特定の人だけが見られるかの管理
・注釈のインポート/エクスポート、教材に書き込まれた注釈を書き出して別の環境で再現する方法が必要
W3Cではこういった部分の標準化に取り組んでいます。すべての必要条件がHTML5、EPUB3で可能になる。
adaption/remixing(教材の適材利用について)
remixingというのはアメリカでは流行語みたいなもので、先生方の需要が高い。
多数の教材の中から先生が選んだもので生徒にカスタマイズして提供する機能。
これを実現するためには教材は細かく分割された単位で(データベースに)ある事。
ただし、教材の著者(著作権者)がここまで分割できる、これ以上は出来ないという設定が出来る事。
日本で教材を使う先生方にこういったカスタマイズが必要かどうかはわからないが、アメリカで先生方に意見を聞くと、こういったカスタマイズを一度使うと大変便利でやめられないということで需要が高い機能
コンテンツについて
どの端末であっても適応した表示ができるリフローラブルなコンテンツも欲しいし、一定の見た目を提供できるコンテンツ(デバイスも固定される)も欲しい
ビデオや音声といったものも欲しいし、入力や応答が可能な(インタラクティブな)ものも欲しい。
多くの出版社は紙の物と同じ(見た目の)ものをデジタルで出そうとする(が、それはどうか?というようなニュアンス)
コンテンツを「読む」のはオンラインでもオフラインでもキャンバス内でもキャンバス外でも、場所に縛られないようにしなければならない
アクセシビリティの内容については、この後河村氏からより詳細な説明があるので、ここでは概要の説明にとどめておきますが、HTML5にはPDFなどに比べて非常に優れたアクセシビリティがある。アクセシビリティ向上のためにタグが追加されている。
EPUB3にもHTML5にテキスト読み上げなど、さらに機能を追加している
ただし、これらはあくまで技術にすぎずそれらを出版社(教材の制作者)が使う為には書籍やテンプレートといった、ガイド等が必要だろうと考えている。
USAの事例紹介
(実際に利用されている、教育システムのデモが行われた)
「アクセシブルな教科書とは?」
河村 宏(特定非営利活動法人支援技術開発機構副会長、DAISY Consortium 理事)
DAISYコンソーシアムは様々な障害を持つ人にとってのアクセシビリティの為の規格を制定する団体
その理事の立場から、そもそもどういった人がこの規格を求めているのか、求められている規格、技術とはどういった物なのか。
それがデジタル教科書という教育の分野でどう取り入れられるべきなのかを解説
河村宏:DAISYコンソーシアムが考えるアクセシビリティとはグローバルなものです。
現在、紙の出版物から閉め出されている人が多いのはどこか、それは発展途上国、中でも多言語の国。文字が読めない、又は読めても自分の母語でない物で書かれた書籍は読めないという人がたくさんいる。
そこで考えるアクセシビリティ。国連でもこの問題について議論されています。
障碍者や技術者だけでなく、国連という場で外交官という立場の人達がこの問題を議論していることに注目してください。
アクセシビリティとは多様な人間のニーズに応えて、情報を提供できるということ。
それには国際的なユースケース、どのような場面で必要とされているかの例の収集が必要です。
標準化団体で規格を決めるというだけでなく、デジタルデバイド(パソコンなどのIT機器を使えない事で情報格差が生まれている)と言える状況をデジタルオポチュニティ(デジタルを使う事で情報格差を解決すること)に変えるために何が必要なのか、それがユニバーサルデザインでありアクセシビリティである
DAISYコンソーシアムが想定するユースケースは、かなりギリギリの状況を考えています。
それは災害などの時です。情報を手に入れられるかどうかという事が生死を分ける場面です。
たとえば「危ない!逃げろ!」と言われたとして、どこに逃げるのか、どうやって逃げるのかそれは事前に知識を得ていなければ分かりません。
情報を得る事と得た情報を判断する事が必要なのです。
災害時に情報を手に入れる事ができるようにするにはどうするべきかを考えなければいけません。
途上国の状況からもユースケースを学べます。
南アフリカでは現在HIVの陽性率が40%近くあります。このような環境では予防の知識だけでなく罹患した人に病気についての知識をもたせる必要があります。この情報は、医学書並に正確なものでなければなりません。
この場合、作成されたマニュアルはどんな人でも読めるように多言語対応する必要があります。(南アフリカで使用されている)11の公用語すべてをカバーを目指しています。
さらに、識字率が低い事を考えて、文字を音声で読み上げる機能も必要です。
アクセシビリティとはそこに書かれている情報がわかる手段を提供することです。
教科書と教材について
コンテンツが一つあって、そこにアタッチメントとして音声、点字、動画(手話)を入れる事で、障害を持つ人が情報を読み取れるようになる。
たとえば、聾者の方で第一言語として手話を取得した人は、文字で書かれた言葉を読み取るのが困難です。手話という手振りや表情といったボディーランゲージと通常の文字では文法の違いや、動作によって意味を読み取るという感覚との違いがあるため、テキストとして表示された言語を結びつける事が難しいのです。
EPUB3には動画が入れられるので表示されるテキストと手話を結びつける事ができる技術に期待しています。
プリントディスアビリティ(印刷された文字情報を読むことができない状態)
視覚障害なども含め「読めない人」は総人口の20-50%を占めると言われます。
これはたとえば、両手が無いとか、パーキンソン病などで四肢が不自由で書籍にアクセスできないといった状態、さらに識字障害であるディスレクシアなども含みます。
通常の人であっても例えば脳梗塞など脳の障害を負う事によって、いままで読めていた文字が読めなくなるといったケースは多く、プリントディスアビリティは潜在的に非常に多くいると考えます。
識字障害であるディスレクシアは世界中におり、総人口の5-10%ぐらい。日本では5%程度存在すると考えられています。
ディスレクシアを抱える子供は、紙に印刷された文字の教科書を読む事ができない。子供に必要な教材が与えられていないことにより学習機会を失う子供が多い。
文章を読み上げるトーキングブックがあればディスレクシアがあっても文章を読む事ができる。
ディスレクシアと一言でいってもその障害は様々で、音声のみであれば理解できる人、音声と同時にテキストをハイライトすれば分かる人、音声を聞きながらであればテキストをたどる事が出来る人など、そのニーズは様々。
これらのすべてのニーズに一つのコンテンツで対応できたらよいと考えている。(つまり一つのコンテンツの中にすべての機能を持たせる)
さらに、音声だけでなくピンディスプレイによる点字の表示などができればよい。
幅広いニーズに一つのソースで応える、一つの規格のプラットフォームに盛り込みたい。
これは、この機能はこっち、この機能はあっちというように分散すると採用しづらくなる。
また、なんでもかんでも機能を詰め込み過ぎてリッチになってしまうのもこまる。環境(デバイス)に合わせて機能が制限できるなどのコントロールが必要
学校・教育・仕事の場においてのDAISY活用
アメリカでは法律によって紙の教科書を作成するところはデータの提出が義務づけられている。
この提出データはフォーマットが規定されておりそのフォーマットにそったデータを提出する。
現在の状況から、すべての生徒がデジタル教科書を使うという状況より、紙の教科書と(ディスレクシアなどの障害に対応した)デジタル教科書との混在のシーンが先に増えるだろうと思われ、共存する環境に合わせた注意が必要になる。
例えば、紙の教科書には何ページという概念があるが、デジタル教科書にはない場合が多い。「○○ページを開いて」といった指示はできない。
教育の場でなくても、たとえば学会のような場でも紙とデジタルが混在することは考えられる。
各国のデジタル教科書普及
ブラジルでは一人1台のデバイス配布を行っている。
韓国もEPUB3で教科書を作っているが、これのアクセシビリティはどの程度のものか不明。
タイは一人1台のタブレットを配布している(小中学校に投入)ただ、ハードスペックが低くアクセシビリティの実現には非力である。
現時点で、アクセシビリティにまで配慮されたデバイスを配布できているといった事例は聞いた事がない。ハードウェアの選定の段階で失敗している事が多い。
教科書の電子化を考える時に、今、紙の教科書から(障害などで)閉め出されている生徒がデジタル化の際もさらに閉め出されるということでは、その生徒はいつ教育を受けるチャンスが与えられるのか。教科書の電子化にはそういう配慮が必要である。
会場でのQ&A
Q 様々な機能が要求されているが、これらを満たすのは大変。それよりもっと簡単な機能で、最低限の実装をしたものでいいからできないかと思う
A すべての要件をすべて満たす必要はない。テキストのみでだして、それを(別の)読み上げエンジンに処理させたりする事もできる。
IDPFもDAISYも「規格」を作っているだけであり、ほんとうにその機能を持たせるかどうかはコンテンツ制作者に任せるしか無い。強制的にやらせることはできない。ただ、規格としては必要とされるすべての項目を設定しておかなければならないということ
Q EPUB3がなかなか広まらないのはエディターの貧弱さなど制作のプラットフォームがないからではないか
A MS WordにEPUB3の書き出しがついた、これがきっかけにならないかと思う。でもそれ以外にもコンテンツの制作ツールが必要だとは思う
「デジタル教科書の開発・導入傾向と機能要件の整理」
上智大学にて教育工学を研究する田村氏より、日本でのデジタル教科書の現状や問題点、デジタル教科書に必要な機能の提示とその機能を盛り込んだデジタル教科書試作開発のデモ
田村 恭久:現在デジタル教科書の導入が盛んな国として、韓国、シンガポール、タイなどがある。日本でも2011年に文科省がデジタル教科書についての提言をだしている。これは単なる紙の教科書のリプレイスではなく、個別学習などアクティブラーニングまで見据えた内容となっており、これにそって現在実証実験が行われ、テスト用に対応する電子教科書などが作られている
電子教科書の問題点としてステークホルダー(利害関係者)が非常に多い事がある。
電子出版であれば出版社、編集者、出版取次、読者ぐらいが利害関係者。
これが電子教科書になると、文科省、教育委員会、出版社、編集者、先生と生徒とステークホルダーがふえ、さらに今までいなかったステークホルダーとして、サーバーやデバイスといった機器の導入者、インフラ管理者、コンテンツの管理者が加わる事になる。
電子教科書での教育は、単にいままでの授業をそのまま(教材を)デジタルにするだけでは不十分だろう。
例えば、日本の教育は「議論」をするためのトレーニングが出来ていないとよく言われる。今日のこのセミナーも大学の講義などと同じく講師がしゃべってそれを(黙って)聞くというスタイル。
小学生ぐらいだと授業中に手を挙げて意見をいうといった授業もあるが、高校、大学と進むにつれて「黙って聞く」スタイルが増える。これで社会にでて「意見をいいなさい」と言ってもムリ。
そういった「議論する」ためのトレーニングなども取り入れた「アクティブラーニング」を教科書に取り入れる必要がある
それ以外にも生徒の学習速度や適応度に合わせた対応が出来る事や、デジタルネイティブと言われる世代への対応。デジタルネイティブ世代は「調べる」事を自然に行う。GoogledやWikipediaでの検索など。これは彼らに取って当然であり、これを抑えて「教科書」の中だけで勉強させよう、この枠からでてはいけないというのはムリ。
デジタル教科書に何が必要なのか、どういう勉強方法があるのか、こういった議論、コンセンサスがほとんどなされていない。
先ほどMarkus Gylling氏のセッション、アメリカの事例で教科書のコンテンツを先生がリミックして使うという話があったが、果たして日本でこれをやって文科省(検定教科書)が許すかというのは微妙ですね
そういったいろんな立場とかはありますが、私としては純粋に技術屋としてデジタル教科書のスペックスタンダードとはどうあるべきか、というのを考えている。
フォーマットとしてはEPUB3を考えているが、EPUBというリフロー型の形式を選ぶ事のデメリットとしてPDFなどとちがってページ指定が出来にくいというのがあるが、そういう事も含めた教授方法から考えていくべきだと思う。
(資料)「生徒用電子教科書に要求される機能」

資料は生徒用電子教科書に必要であろう機能(認証/著作権/内容表示/関連情報/学習者による情報追加)と各項目の詳細図
この程度の機能は必要となると考え、デジタル教科書の試作品を作成した。
(資料、および試作品のEPUBデータはhttp://www.epubcafe.jp/egls/epubseminar28からダウンロードすることができる TamulaboDigitalTextSample0604n.epub というファイルをダウンロード)
設定した各項目を実際のEPUB3ファイルに実装し、各デバイスでのテストを行っているが、クリアできない端末が多かった。
機能の実装にはjavascriptを使っているものが多く、kindleなどそもそもjavascriptの動かない端末では動作させられなかったため。
しかし、その中でも一番成績のよかったiBooks3 (iPad2)でも全項目の5割程度しかクリアできなかった。
デモではipadが配布され、実際にデジタル教科書の中に搭載された掲示板機能や手書き入力などを試す事ができた。
触った感想
・javasceriptなどがふんだんに盛り込まれているせいか読み込みなどが遅く、アクションごとに反応をまつ感じ
・教科書から掲示板などのWebブラウザのサービスにうつると、教科書に戻るのにブラウザ閉じる→教科書アプリをダブルクリックなどの動作が必要でスムーズではない
・掲示板、手書き入力などの機能が用意されているが、インターフェースや動作感などは特に練り込まれたものではないので、実際にスムーズに使わせようと思うともっと練り込んだ実装が必要だろう
また、実装として今回のものはとりあえず最低限の機能を実現しただけなので、たとえば掲示板にアクセスし文字を書き込む機能では書き込まれた内容をクラス単位、学年単位、学校単位といった管理をする機能などは搭載していない(多分そちらは教科書側の機能というより管理サーバー側の機能になるだろう)
電子教科書制作におけるこういった技術的制約、ハードウェア的制約をどうやって乗り越えていくか。
技術的に作りやすく、使用者(生徒)の満足度をあげていかなければならない。
技術屋としては、EPUBリーダーの開発ではなく、WEBブラウザのアドオンで実装できないかと考えている。これはEPUBリーダーに通信機能をのせようとすると大変難しいのだがWebブラウザのアドオンであればここが簡単にクリアできるため。
会場でのQ&A
Q 試作は機能を実現するためにjavascriptをかなり利用しているがEPUBでjavascriptの使用は認められるかどうか
A
Markus Gylling氏より回答
idpfとしてEPUBの中でjavascriptを使用する事を禁止しているということはない
javascriptの使用については長期的に見てそのjavascriptが動作できなくなる可能性もあるだろうということ。ただ、これを使用させずにテキストベースだけですべての要求仕様に応えようとするとあと30年はかかるだろう
まず、今必要な機能を実装するのにjavascriptで作ってみて、その中でどうしても必要な物だけを規格として規定していけば良いと思う。
Q こういった電子教科書のテンプレートのようなものを公開してもらえないか
A テンプレートの作成や配布は今後の課題(とりあえず、今回のデモファイルは公開されている)
Markus Gylling氏より回答
idpfでライブラリを整備しようとしている。中心ターゲットはテキストブックで。
Q これだけ様々な機能、要求にEPUBで対応しようとするとどうしても動作は重くなると思うが、たとえば電子書籍作成でいえばADPSなど他にも制作ソリューションやフォーマットなどはあるなか、あえてEPUBを選択する意味はあるか
A 他のソリューションによるフォーマットと比べた時に、作成物を日本中に配るときのトータルコスト、他のソフトを使ったときの総コストなどを比較して選択するべき
Markus Gylling氏より回答
性能について言えば、常にアプリケーションベースのものがWebベースのものより上になるというのはある。ただ、これはいずれ追いついていける話ではある
「ベネッセの電子教材制作について」
阿部健二、桑野和行(ベネッセ)
「チャレンジ」などで有名な教材販売会社のベネッセの電子教材への取り組みについて
ベネッセでは教科コンテンツをXMLで管理し、紙面の自動組版はもちろん、XMLからの多展開を行っている
今回は、実例を交えて具体的な取り組みについて説明
ベネッセのデジタルコンテンツへの取り組み
ベネッセの電子教材への取り組みは80年代から行っている。古くはファミコンにつなげて使うソフト、その後DSなどのゲーム端末で使える学習ソフトなど。
現在ではiPod touchやベネッセオリジナルのAndroid端末を提供している。
ベネッセのデジタルコンテンツの管理方法
教材として使用されるコンテンツは色々あるが、その中でドリル系商品の例をとって説明
ドリル系商品のなかで使用される教材「問題・回答・解説」これがコンテンツである
このコンテンツを形にするときのレイアウトは商品や規格によって変わるものである。
なのでコンテンツである「問題・回答・解説」をXMLコンテンツとしてサーバで管理、コンテンツの入力はWEBブラウザを通して外部の執筆者でも行えるようになっている、コンテンツを蓄積したDBのXMLサーバからPDFやXSLTなど様々なフォーマットに対応して書き出しを行っている。
コンテンツ数はかなり多い。
現在のシステムのレベルはかなり高いと自負しているが、自社独自規格として構築されているので、現在XMLスキーマのHTML5版を作成中である。
これは将来、自社以外のコンテンツホルダーとのデータのやり取りに備えてということと、おこがましいが教育系メタデータの標準作りの露払いになればと考えている。
EPUBへの取り組み
昨年度からEPUBへの取り組みを進めている、現在テスト制作を行っている段階
コンテンツ管理システムから自動アウトプットでEPUB作成、一つ一つ手作りではないので大量生産可能
EPUBのリフロー型のレイアウトに固執している。これは、一つのファイルでマルチデバイスに対応できるというところに魅力を感じるため
アクセシビリティに関しては文字サイズの変更などに対応する程度
作成したEPUBについて
数式、ルビなど組版的要素については(現在はまだ合格基準に達していない部分があるが)いずれ適用となるだろう、というか紙と同じ見た目にこだわるのはナンセンスと考えている
解答の正誤判定や補足テキストのポップアップ表示などはjavascriptを使って実現。これはビューワーやデバイスのパフォーマンスに左右されるというところが改善しなければならないところ。
デモではMac上のreadiumで軽く動作していたが、デバイスなどによっては動作がわるくなる。
また、数式などの複雑な組版も画像ではなくテキストでの表示に対応しているが、解答者の入力にその組版を入力させる事ができないので、数学の問題などはどうしても記入式の解答ではなく選択式にせざるを得ないなど技術的な制限がある
EPUB導入における課題
- ビューワー
コストは出来るだけ抑えたいが、パフォーマンスは問題。特にjavascriptを使った時のパフォーマンスには難あり
Readium SDK、WEBブラウザのEPUBビューワー機能の追加に期待している
コンテンツホルダーとしてはDRMにこだわりたいが、ユーザーの利便性と秤にかけつつの対応となる。最近ではハリーポッターのDRMフリーなどの事例もあるし、そういった事例を参考にしつつ考える
- コンテンツ制作者の頭の切り替え
どうしても今まで制作してきた人間は「紙面と同じ見た目、品質」を求める
リフロー型という特性からデバイスなどによって体裁が変化するものだが「体裁ごとに校正しなければいけないのか」といった意見が出てしまう
教材という性質上「分かっていない人が分かるようになるための物」であるので、体裁によって理解の妨げになるようではいけないと考えている。
教育コンテンツ制作の悩み
メディアの進化に対応していくために制作費が増加する
電子書籍は漫画や文芸書などが牽引役となっているので、技術の進化もこういった分野からで、教育分野の技術進化は遅れがち
例えば、数式や多重下線など、教材コンテンツに必須の複雑な体裁がなかなか対応できていない。教育における電子書籍の標準規格をどう作るべきかと考えている
電子化による学習機会の拡大やアクセシビリティへの対応は必要だが、コストとの兼ね合いもあり、以下に制作コストを抑えつつ対応するか
今後は、レンダリング技術の歯科と(教材のために必要な機能の)規格標準化に期待している
会場でのQ&A
Q 検定教科書を作成している会社などと話すと総じてEPUBの採用には後ろ向きです。曰く「表現力が十分でない」「Fontの問題」「プロ向けのオーサリング環境がない」といった所。コンテンツホルダーにEPUBを採用してもらうにはどうすればいいと思われますか
A
日本電子出版協会 副会長 下川氏より回答
EPUBの標準化というのはできているが、それぞれの課題は山積みです。今、この時点でどうかというより今後、これからこれらの問題に対処していこうというところです。
Q コンテンツ作成者と話をすると、ほとんどがInDesignだPDFだとレイアウトやビジュアル(重視の制作手法)にこだわるのだけど、ベネッセさんがXMLからの自動生成という、コンテンツ中心にした制作フローを採用しているのはなぜか
A ベネッセ 教材制作において、年間大量の制作物を作らなければならないのですが、教材という性質上、間違いがあってはならない。大量の制作物そのすべてをチェックするとなると校正の負荷が大変なものになる。なので、ビジュアル中心にこだわらず、校正されたコンテンツを用意しておいてそれを流用するという、コンテンツ中心のワークフローにしている。
【感想】
デジタル教科書の現状と今後の展望についてのワークショップということで、現在のデジタル教科書…というより、教育とデジタルを巡る問題点などが色々な視点から提示されるとてもいいセミナーでした。
Markus Gylling氏と田村 恭久氏のセッションではそれぞれ「デジタル教科書を使った教育を行う上でデジタル教科書にはどういった機能が必要とされるのか」といった問題について
「教科書」というコンテンツだけを電子化すればいいという物ではなく、それらを管理するサーバーや管理ソフト、表示する為のデバイス、ハードウエアの対応が必要であり、さらにそれらを用いた教育の方法についても、考えていかなければならない。つまり、紙の教科書をそのままiPadに表示させてそれを見ながら読むだけの授業ではだめだということですね。
田村氏はその上でどういった機能が必要かを実際に電子教科書の機能を試作してテストしていますが、現状のEPUBの規格では要件を満たせないということも確認できました。
これはフォーマット(および制作ソリューション)としてEPUB以外のものを選択するという解決策もありますが、その場合教科書という公的なものが特定営利企業のフォーマットを採用する事による問題を(営利的なものだけでなく、そのフォーマットがいつまで使えるかといった事も含め)考えなければいけません。
また「教科書/教育」という公共性が必要とされるものにおいてのアクセシビリティの問題。
教科書という性質上、アクセシビリティというのが必要になってくるのですが、河村氏のセッションではアクセシビリティというのが一般的にイメージされる障碍者のものだけでなく、もっと広く情報にアクセスできない人のための物である事、教科書ひいては教育においてデジタル化したときにこれらの人が再び取り残されるようなことのないようという主張でした。
DAISIコンソーシアムの理想とするところはわかりましたが、実際にどこまでこれらの機能を実装できるか、すべきかというところはやはり制作コストを考えると難しい問題。
もちろん、全部を実装する必要は無く、最低限これだけはという実装になるとはおもいますが、実際にデジタル教科書の作成が始まったらこの「最低限この機能は」というところもルール化されるのでしょうか。
最後のベネッセさんは、今回のスピーカーの中で唯一「実際にコンテンツを作り、それを販売している」という意味で一番実践的、現実的な内容だったと思う。
大量のコンテンツ(問題等)を何度も形をかえて使い回すという前提でシステムを構築し、実際に運用されている。
教育コンテンツということで、独特の組版(数式など)の問題等、この分野ならではの悩みなどは、実際に制作している立場でないと出てこないものだと思った。
ある意味、そこまでの3者が「理想」を語る中で「現実」をしっかりとらえているセッションだったと思う。
このセミナーを聞く限り、問題は山積みでデジタル教科書(というかデジタル教育)の普及はまだまだかな…と思う反面、なんらかのメリット(たとえば紙の教科書のコストよりデジタルの方が遥かに安いなど)があれば、あっというまに普及するかもしれないと感じた。
問題はデジタル化にせよ、アクセシビリティの実現にせよ、かかりすぎるコストをいかに抑えるかだと思う。
国立科学博物館でたぬきフォントが使われていた
国立科学博物館の企画展「グレートジャーニー人類の旅展」をみてきました。

(ちなみに会場内特定の展示物以外は撮影OKでした)
展示は非常に興味深く、面白かったのですが、展示物の説明パネルにちょっと特徴のあるフォントが使われてまして
これなんだろう?とTwitterで質問
これなんのフォント? twitter.com/akane_neko/sta…
— あかねさん (@akane_neko) 2013年6月4日こういうのに詳しい人がやたら揃ってるのが私のTLで、すぐに答えが。
@akane_neko これかも tanukifont.sblo.jp/article/414328…
— chalcedony@ちばっこさん (@chalcedony) 2013年6月4日「たぬき油性マジック」というフォントだそうです(たぬきフォント)

聞いてから答えがでるまで1分かかりませんでした。すばらしすぎ。
というか、デザインする人ってこういうフォントがあるとかよく知ってる。
私は普段製版とか出力側の業務で、モリサワだフォントワークスだ、小塚だヒラギノだとメジャーどころのフォントしか扱わない事が多いのでこういうなんていうか、メーカー製でないフォントの情報には疎いのだけど、調べてみるとこのフォントいろんなところでじわじわ使われてるんだね。今回の展示にはこのフォントはとても雰囲気があっていたと思う。
製版側の頭でみると、このフォントで入稿してきたら「アウトラインとってこいやーーー!!!」としか考えられないのだけど、いざ入稿されたときに「なにこれ?!こんなフォント知らんわー!」って慌てないようにこういうフォントの知識ももっとかないとなー、とか思いました。

▲「もっと精進しろやーーー!がおーーーーーー!!」
写植展をやってました
平日にお休みを貰えたので、ちょっとぶらぶらしようかなと根津の辺りへ。
お腹がすいたので何か食べ物屋さんでもないかなーと路地裏を歩いていたら

▲なんかやってる!

▲ギャラリーらしい
ギャラリー「華音留」で「写植展」というのをやってました。

▲中に入ると写植の文字盤がずらりと。

▲文字盤、バラ売りしてます。

▲分解された写植機。

▲写植の歌。歌える人ってどんだけいるんだ…

▲文字盤もって、文字をみる

▲変体かな
ちなみにこの展示「見る人が見れば超面白い」という類のものなのですが、展示をしてらっしゃる方がパンフレットや資料をどんどん繰り出して色々と説明してくれます。

▲写植機スピカのパンフレット
その説明が分かる人にはなお、面白いだろうとおもいます(すいません、私半分ぐらいしかわからなかった…)
今の展示は今週末(6/8)までなのですが8月13日から2週間の予定で再度写植展をやるそうです。
こういう写植の展示とか珍しいので興味のある方はぜひ行ってみるといいと思う。そんで展示者の人と語り合うといいと思う(むしろこの展示、あの方と話す方がメインじゃないかと思う)
ちなみに、写植展に気を取られてるうちにランチタイムはおわってしまい昼ご飯たべそびれました。

▲しかたないから甘味処でクリームみつまめ。うまかったっす。
猫でもわかるPostScriptとPDFの昔話
はじめに
この話はTwitterで大暴れの最強初心者、猫○嬢の発した
▲一応鍵アカなんでモザイクかけとくと、なんていうかどこから突っ込んでいいやら分からないほど混乱した質問への答えとして書いた連続ツイートを元に多少解説などを加えたものです。
彼女の一連の疑問ツイートなどはご本人がTogetterでまとめてますのでそちらをご覧ください(「PDFとPSの関係がわからなくなってきた時のこと」)ここではPostScriptとPDFをDTPの視点から解説しています。簡単に説明するためあえて細かい説明などは省いた部分もあります。
同じように「なんかこの辺よくわかんない…」って思ってるDTP従事者の理解の一助になれば幸いです。

昔話
昔Adobeという神様が、テキストで図形を表現するためにPostScriptという言葉を作りました。この言葉は▲や■などの図形を言葉で表現できました。神様はこの言葉で書いた図形が紙に出力できるように、この言葉をビットマップに置き換えて紙に出力できるPostScriptプリンター(CPSI)を作りました。

次に神様は書いた言葉をモニタ上で図形の形で確認したくなりました。そこで神様はこの言葉をモニタ上で図形として表示してくれるソフトIllustratorを作りました。
Illustratorが作る子供(ファイル)は皆PostScriptで書かれていました。IllustratorはPostScriptでいろんな形を作れるソフトになりました。Illustratorが作った子供はPostScriptプリンター(CPSI)がどんどん紙に出力してくれました。

時がたって、神様はIllustratorがもっと違う形も作れるようにしようと思いました。いままでと違ってスケスケのオブジェクトなんてどうだろう
ところが、生まれてからずいぶんたったPostScriptは、神様の言う「透明」がどうしても理解できません。

そこで神様はIllustratorが産み落とす子供をPostScriptから少し進化させた形(PDF)にすることにしました。
若いPDFは透明も使えるし、いままでのPostScriptにはないページという考えやレイヤーという考え等も理解できました。
ですが、いままでPostScriptとともにがんばってきたPostScriptプリンター(CPSI)達は新しい考え方の若者を理解できず、紙に出力してやることができません。

神様は、プリンター達も少し進化させて、PDFを理解して紙に出力してやることができるAdobe PDF Print Engine(APPE)というエンジンを作りました。
APPEは「透明を出したい!」というPDFを理解し、紙に出力してやることができました。

つまりPostScriptが進化してできたPDFはPostScriptの子供のようなものなのです。PostScriptは言語として世に生まれましたがPDFは言語であるPostScriptが作り出したドキュメントの形式です。
猫よりもうちょっと上の人のための解説
昔Adobeという神様が、テキストで図形を表現するためにPostScriptという言葉を作りました。
(1)神様の中の人の名前はチャールズ・ゲシキーさんとジョン・ワーノックさんと言います。元々はゼロックスの研究所でPostScriptの元になる技術の研究をしてたんですが、独立し、PostScriptの技術で商売をする会社を立ち上げました。これがAdobeです。
神様はこの言葉で書いた図形が紙に出力できるように、この言葉をビットマップに置き換えて紙に出力できるPostScriptプリンター(CPSI)を作りました。
(2)CPSIというのはConfigurable PostScript Interpreterの略ですが、PostScriptで書かれたテキストをビットマップに変換してくれるソフトウエアの名前です。CPSI RIPではこのエンジンがRIP上で送られてきたPostScriptデータをビットマップに変換しせっせと出力してくれています。
次に神様は書いた言葉をモニタ上で図形の形で確認したくなりました。そこで神様はこの言葉をモニタ上で図形として表示してくれるソフトIllustratorを作りました。
(3)当初テキストとして書かれたPostScriptを図形で確認するためには、いちいちプリントする必要がありました。これを画面上で確認するために作られたツールがIllustratorの元になったソフトなのだそうです。
Illustratorが作る子供(ファイル)は皆PostScriptで書かれていました。
(4)Illustrator v8まで、Illustratorのネイティブファイル(aiファイル)はPostScriptで記述されていました。つまり、ネイティブファイルをテキストエディタで開いてみると、PostScriptの記述テキストがずらっと並んでいたわけです。
時がたって、神様はIllustratorがもっと違う形も作れるようにしようと思いました。ところが、生まれてからずいぶんたったPostScriptは、神様の言う「透明」がどうしても理解できません。そこで神様はIllustratorが産み落とす子供をPostScriptから少し進化させた形(PDF)にすることにしました。
(5)PostScriptは、様々な処理ができる柔軟な言語として開発されたのですが、そのため却って、表示が環境に左右されてしまったり出力エラーを起こすなど扱いづらい部分もありました。そこでAdobeはもっと安定してどんな環境でも一定の表示ができる文書ドキュメントとして、PostScriptの技術からデータを表示、印刷する部分に特化し発展させたPDFというフォーマットを作りました。PDFはPortable Document Formatの略、つまりどんな環境に持ち運んでもちゃんと表示印刷できるドキュメントの規格として作ったのです。
さて、Illustratorは v9から新しい機能「透明」を取り入れたわけですが、この新しい機能である「透明」が従来のaiファイルつまりPostScriptファイルのままではどうしても実装できませんでした。古い規格であるPostScriptにその新しい機能をのせるのは困難だったのです。でも、新しいフォーマットであるPDFなら、透明という機能を盛り込む事ができました。
そこで、Adobeは、Illustratorのネイティブファイル形式としてそれまでずっと使われてきたPostScriptをやめて、新しいフォーマットであるPDFを採用することにしました。
これはIllustratorの歴史すなわち、PostScriptという技術を中心に回ってきたDTPの歴史がPDFという規格に大きく舵を切った大転換の出来事でした。
ところが、いままでPostScriptとともにがんばってきたPostScriptプリンター(CPSI)達は新しい考え方の若者を理解できず、紙に出力してやることができません。
(6)IllustratorのネイティブファイルはPostScriptからPDFに変更されましたが、そうはいっても、IllustratorからCPSIのプリンターで出力する時や他のソフトウエアに渡す時などは従来のPostScriptやEPSというファイル形式を使わなければならず、そのとき「透明」のままのデータでは渡す事ができません。
そこでIllustratorからPSやEPSに書き出しするときに「透明」が使われている部分を「透明」の見た目のとおりにパスで切ったり、画像化したデータに変換して「PostScriptで透明と同じ見た目に合わせる処理」をやる事にしました。これがIllustrator上の「分割/統合処理」です。アプリケーションは、こうやって「透明」部分を分割/統合したデータにしてCPSIの出力に渡します。CPSIはこの分割統合された部分を出力することで透明の見た目を再現します。
神様は、プリンター達も少し進化させて、PDFを理解して紙に出力してやることができるAdobe PDF Print Engine(APPE)というエンジンを作りました。
(7)Adobe PDF Print Engine(APPE)はPDFを解析しビットマップデータに変換して出力するエンジンです。もちろんPDFに含まれる「透明」も処理する事ができます。他にも、PostScriptではできなかったデータ内のページ処理や、レイヤーごとの処理などPDFの機能を活かした処理が可能です。
Illustrator v9が発売されたのが2000年6月、APPEが発表されたのは2006年4月。実際にAPPEを搭載しPDFをネイティブに処理できるRIPが登場しはじめたのは2007年頃(APPEを搭載したTrueflowSEの発売は2007年8月頃)です。
こんなに長い時間をかけてもいまだにPostScriptがバリバリ現役で、PDFワークフローに主役交代していないという事実にちょっとくらくらしますが。
いずれにせよ、Adobeとしては「これからはPDFだよ」と、とっくの昔に切り替えているのです。
PostScript技術から始まったAdobeという会社は、その後多数の会社やソフトウェアの買収などを繰り返し、今では映像やWeb、画像など様々なソフトウェアを売る会社になっています。でもそんな中でも、PostScript技術はIllustratorやPDF、Acrobatなど形を変えながら、いまもなおAdobeの中心を支える技術です。いわばAdobeの屋台骨だといえるでしょう。
そして私たちが従事するDTPという仕事は、Adobeの作ったPostScript、PDFがすべての土台であり、その世界の中で仕事をしています。
だから「Adobeは神」っつっちゃってもいいんじゃね?かなり横暴だけどな!
謝辞
文中のすばらしいイラストはすべて@moriwaty画伯に描いて頂きました。
イラストによって、なんとなく話の方向性が違うところに向かっているような気もしますが(笑)ありがとうございした!
ニス加工名刺を作ろう!参加者募集
以前参加した「特殊加工(ニスで疑似エンボス)の名刺を作ろう!」企画「みんめプロジェクト」が再び参加者を募集しています。

{kind=link}
「みんめプロジェクト」は「あまり使う機会のない特殊加工、みんなで集まってやれば安くできるじゃない!じゃあみんなでニス加工の名刺でもつくっちゃおっか!」という、特殊加工体験プロジェクト。
単に安く特殊印刷(ニス加工)の名刺を作ろうというだけじゃなく、みんなで(Twitterなどで)わいわいやりながら名刺を作ることによって、データ作成から印刷までその過程を楽しもうという企画です。
前回私が参加した時の感想などはこちらのレポート(疑似エンボス(ニス加工)の名刺をつくりました)に書いたのですが、ただ単に名刺を作るだけじゃなく、特殊加工のデータの作成を実体験しながら、希望者は印刷現場の見学、出来上がった名刺の郵便交換会(デザイナーさんなどの凝りに凝った名刺がずらり!)など、様々な行程を楽しめました。

▲前回参加したとき希望者同士の名刺交換会で手に入れた名刺。見てるだけで楽しかった…!
今回はfor dot-aiということで、6月29日開催のIllustratorユーザーのイベントdot-aiで凝った名刺を交換したい!という人にあわせた締め切り設定になっておりますが、もちろん、どんな方でも参加OK。
ちょっと凝った名刺を作りたい!という方におすすめです。
作成する名刺は
6C×6C(プロセス4C+ニス版2C)のフルカラー疑似エンボス両面200枚。アートポスト180kg
両面フルカラーでニス加工というかなり豪華な仕様です。
ニス版の2Cというのは、ニスを2回重ねる事でツルツルとザラザラという2種類のテクスチャができ、それがエンボスのようなやや盛り上がった効果になるという物です。



いずれの写真も@yamo74氏撮影
▲ニス加工の見本
@yamo74氏が作ったみんめ説明用のページ(#minme_returns)には他にも色々とサンプルの写真や、制作についてのQ&Aが載っています。
値段や締め切りなどは賢工印刷さんのみんめプロジェクトページでご確認ください。
このプロジェクトの面白いところは参加者のほとんどがデザイナーや製版、印刷担当など印刷やデザインのプロであるところ。
そんなプロ達が「どんな風になるのかな?(・∀・) やってみよう!」と持てるテクニックのすべてをつっこんだ無茶ぶりデータを出力に!
裏のテーマは「(賢工印刷のみんめ担当者である)@hakubaouji氏を泣かせよう!」なんじゃないかと思うぐらい、色々な事を試してます。
「そんな事して、ほんとに出力できなかったらどうするの…?」と心配するなかれ。プロジェクトでは事前に一回の本機校正が組み込まれており、無茶なデータはそこで一度テストができます。というか、テストが出来るからこそ皆色々とお試しができるわけですが…。本機校正は様々なパターンのテスト用と割り切って、本番でガラリとデザインを変える人も多いです。
もちろん、本機校正前にも、データの作り方やチェックなどはTwitter上で@hakubaouji氏に教えてもらったり実際のデータを見てもらったりもできますし、ハッシュタグ#minme_dotAiをつけて疑問をつぶやけば、他の参加者(百戦錬磨の人たち…)からも回答が貰えるかもしれません。申し込み前に色々質問をしてみたい方はTwitter上で@hakubaouji氏に直接どうぞ!
普段「印刷の人にデータの作り方を質問したいけど、なかなか答えを貰えない」とモヤモヤしている方はこの機会に印刷現場の人に直接質問をしてみてはいかがでしょうか?
もちろん、「こんな作り方で表現したいけど、出力ででるかどうかわからない…」という実験データのテストの場としても!
申し込み開始は5月20日から!賢工印刷の@hakubaoujiを泣かせてやるぜ!というツワモノの参加をお待ちしております!